The Data Whisperer: Reelgood’s ML Algorithm for Flawless Content Matching
For major streaming services and consumer tech platforms, achieving an accurate, real-time picture of global video content is the ultimate metadata challenge.
With hundreds of streaming services, millions of titles, and countless regional variations, accurately identifying and tracking every piece of video content is a massive technical challenge.
Whether analyzing competitors’ catalogs and availability, managing your own content’s rights or building search, discovery, or recommendation features, it’s not enough to know that a show exists – you need to know exactly which version of that show is available, where, and when – even when the data you get is messy, localized, or incomplete.
Legacy systems – which rely on rigid rules like matching exact titles and release years – fail spectacularly at this task.
At Reelgood, we moved beyond the basic checklist years ago. Our solution is a proprietary Machine Learning (ML) matching algorithm, a specialized tool that acts as a “data whisperer,” understanding content meaning even when the metadata is full of noise.
This advanced approach is the engine behind our speed and accuracy, ensuring you get the most precise content data faster than any purely human or simple rules-based system.
At Reelgood, this is the problem our Machine Learning team focuses on every day.
The Challenge: Data Inconsistency is Global
Why is matching content so challenging?
Content data is inherently inconsistent, especially at a global scale. How so?
On the surface, TV and movie metadata sounds simple — a title, cast, and where it’s streaming. In reality, it’s one of the messiest data challenges in entertainment.
The Core Problem with Entertainment (TV & Movies) Metadata
- There are no industry standard IDs. Every streaming service — Netflix, Hulu, Disney+, Prime Video, and others — uses its own internal ID system leading to inconsistency across services
- The same movie might exist on four platforms, each with a completely different ID.
- With no industry standard, it’s nearly impossible to align data across services.
Inconsistent TV & Movie Metadata
- Even when two platforms have the same title, their details rarely match.
- Titles, years, cast lists, genres, etc. vary by service and can be ambiguous (e.g., same-name titles, runtimes and release years don’t line up)
- Even something as small as a name spelling can break the link between records
Dynamic Industry Environments
The challenge doesn’t stop there. If you’re trying to manage any set of metadata and accurate, real-time streaming availability, you’re facing:
- Continual delays in updates of newly dropped episodes and shows
- Streaming catalogs changing constantly; licensing deals shift weekly causing titles to continually move among services
- Titles constantly shifting between services
- What’s on Netflix today might appear on Prime tomorrow — or disappear altogether
- Never-ending metadata and availability maintenance and updating (This means the data can’t just be “cleaned” once. It needs continuous monitoring and refreshing.)
Multiply that across continual industry M&A and 300+ global services, and you begin to see the scale of the challenge.
The problems our ML is specifically engineered to solve are the difference between a functional product and a best-in-class user experience.
Compounding the problem: not every piece of metadata is standardized or complete.
Think it’s manageable? Here’s what you’re facing:
- Localization & Semantic Variation: Titles and descriptions differ across regions. For example, matching “Harry Potter and the Sorcerer’s Stone” (US) to “Harry Potter and the Philosopher’s Stone” (UK) is impossible for simple string-matching tools; a basic text-matching algorithm sees two completely different strings, and thus different content.
- Sparse or Missing Data: A data feed might only provide a title and a director and an incomplete cast list, leaving out critical identifiers like release year or detailed descriptions.
- Multi-Language Discrepancies: Matching international content that exists only in local-language metadata, or which is excluded entirely from U.S.-centric master lists like IMDb, is a common failure point for less sophisticated providers. For example, a title from a Danish feed with a description in Spanish is useless to a system that can only compare English text.
- Permutations and Typos: Minor variations in names, abbreviated credits, multi-part series and sequels, or accidental typos shouldn’t prevent a match, but they will in legacy rule-sets.
Legacy metadata providers have long relied on rigid rule-based or manual processes to reconcile these differences. But these approaches simply can’t keep up with the speed and scale of today’s streaming ecosystem.
Manual review can take weeks for large catalogs and still miss new releases and recent episodes, as well as critical nuances, especially across multiple languages. These approaches cause errors, create duplicates, and introduce delays.
Reelgood’s ML-Powered Precision Engine
Reelgood’s content matching algorithm is a proprietary application of advanced models, fine-tuned by years of domain expertise and trained on millions of data points from our comprehensive database of TV shows & episodes and movies.
It moves beyond exact text matching using advanced concepts from natural language processing (NLP) and vector mathematics to understand the semantic meaning of content.
1. Tokenization and Embeddings: Translating Meaning into Math
At its core, our ML system uses an encoder model to process all available metadata, fine-tuned on our massive, curated entertainment dataset.
- Data Vectorization: This metadata (e.g., titles, descriptions, cast, crew, genre, and more) is processed using tokenization. This process breaks the text down and converts it into dense numerical vectors (or embeddings).

Using machine learning and semantic analysis to identify similar content
- Capturing Context: Unlike basic keyword counts, these embeddings plot the content in a high-dimensional space where meaning dictates proximity. This is the difference between simple string matching and true semantic understanding.
- For example: An entry with the description, “A young wizard attends a magical school,” will have a vector close to an entry that says, “A boy discovers he is a sorcerer and enrolls at Hogwarts,” even though the wording is completely different.
2. Cosine Similarity: Quantifying Confidence
Once content is represented by vectors, we use Cosine Similarity to calculate the distance between the vectors, to determine the ‘match confidence.’
- The Calculation: While sounding complicated, this method simply measures the angle between two vectors. If the angle is small, the vectors are highly aligned, indicating a strong semantic match. If the angle is large, there’s not a strong semantic match, indicating that the content is likely different.
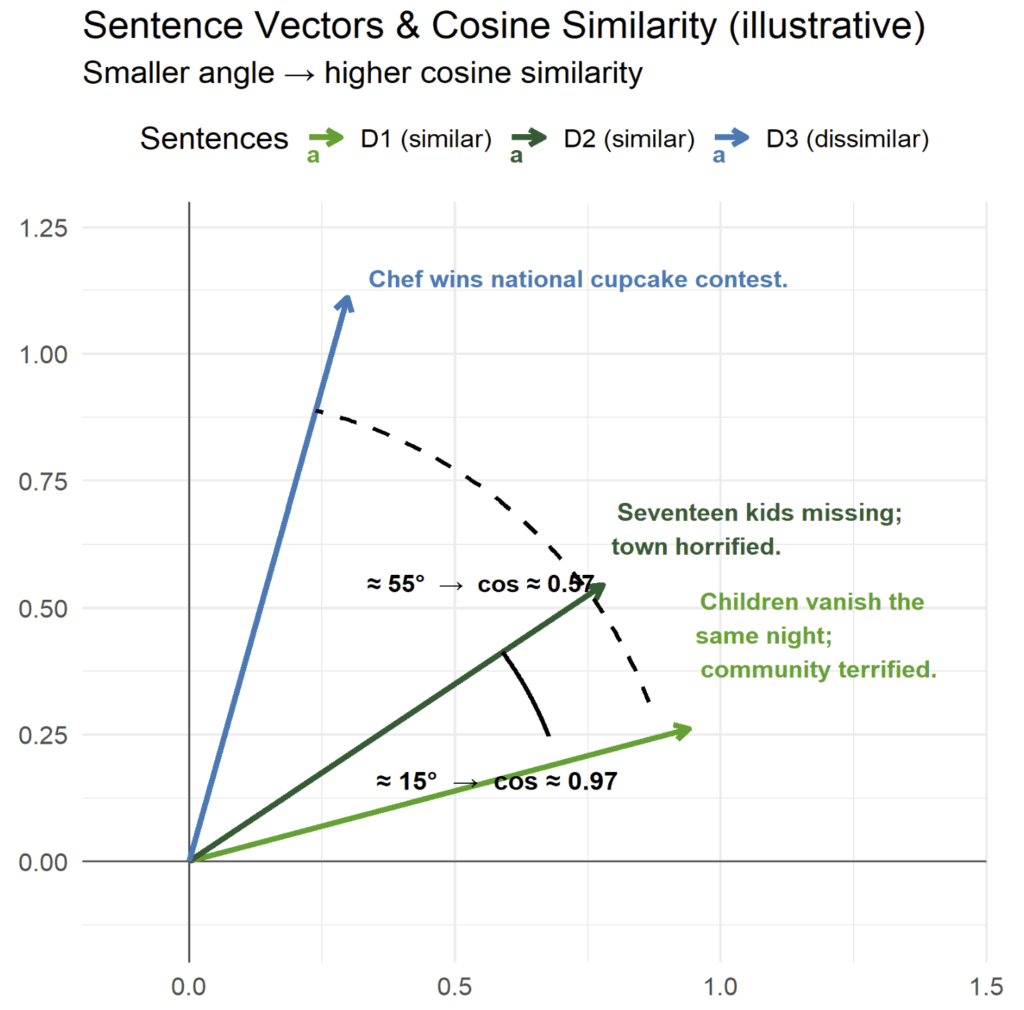
Vector math enables high accuracy content matching based on semantic
- The Precision Boost: This capability is crucial. Where a basic fuzzy logic check might only show a 66% similarity score due to word changes, our ML model can achieve close to 100% match confidence because it understands the shared context.
- The Result: This gives us a single, precise metric: the match score. We apply a highly conservative match threshold to ensure we minimize false positives, which are costly for client systems. This conservative tuning, supported by the deep semantic understanding of the ML, underpins the trust our clients place in our data.
3. Multi-Language and Localization Mastery
Our model is deliberately trained to be multilingual.
Because the ML layer focuses on the underlying semantic meaning captured in the vector, rather than the literal characters, it can match content across different languages. This is crucial for international platforms where titles and descriptions are sourced in dozens of languages.
For example, it can accurately compare a movie’s description in Spanish against the English version of a master title, enabling you to manage the complexity of global, multi-territory metadata seamlessly.
Why It Matters: Speed, Precision, and Scalability
Reelgood’s ML-powered approach solves the most pressing data challenges for video and consumer tech companies with unsurpassed speed and proprietary advantages:
| Key Outcome | Reelgood’s ML-Driven Approach | Traditional/Legacy Systems |
|---|---|---|
| Matching Speed / Refresh Cycle | Minutes (new updates occur every five minutes as we process millions of data points across 300+ services) |
Weeks (for manual review or limited rules-based automation) |
| Accuracy | Extremely High (High 95% threshold and semantic understanding reduces costly false positives) |
Prone to False Positives (due to poor quality data) or False Negatives (due to rigid rules) |
| Scope | Handles sparse data, meaning, complex variations, and multi-language text at scale. | Requires near-exact alignment of fields; fails on variations, content with missing fields or inconsistent localization. |
| Foundation | Fine-tuned on millions of proprietary data points collected over years. | Relies on simple, generalized public datasets or minimal training data. |
| Quality | 100M+ consumer users surface issues that train/improve models and catch edge cases faster than manual systems | Rely on manual processes that are error-prone, create duplicates, and introduce delays |
By implementing our ML engine as the second tier in our robust multi-tiered matching funnel, we can clear the toughest matches quickly.
Before machine learning, matching millions of titles across hundreds of sources could take weeks of manual effort.
|
(If you don’t believe us, ask two of the largest tech companies in the world!)
How We Solve The Entertainment Metadata Challenge
Reelgood’s machine learning system tackles this complexity in real time.
- It continuously ingests metadata from hundreds of sources
- It analyzes every field — title, cast, crew, runtime, and more
- Within milliseconds, it determines whether two records represent the same title or not
- The system runs 24/7, automatically correcting errors as new data appears
The Outcome: Better Discovery and Data Integrity
The strength of any machine learning system depends on the quality of its data. Reelgood’s advantage comes not only from our algorithms but from the depth and completeness of our metadata, which provides the rich training foundation necessary for such high performance.
For partners across the streaming content and consumer tech ecosystem, this means:
- Faster Onboarding of new catalogs and regions
- Higher-Quality Metadata due to the ML’s ability to correct for small-scale anomalies and fill data gaps
- More Reliable User Experiences because the availability information is accurate
The Takeaway: Reelgood’s machine learning approach to content matching turns one of the entertainment industry’s toughest data problems into a solved one; it is the fundamental reason we can promise and deliver the most accurate, most complete, and fastest entertainment (TV shows & episodes and movies) metadata in the market.
If you’re tired of struggling with your metadata and streaming availability’s completeness, accuracy and timeliness, let’s talk.
We’re happy to share how some of the largest companies in the world rely on Reelgood’s clean, unified, real-time streaming data technology.