The Measurement Gap: What Most Streaming Services Are Still Missing
Next in our series on the Reelgood team’s 2026 Streaming Industry Predictions.
Key Takeaways
- Most streaming services lack real-time visibility into competitors’ and partners’ catalogs, creating dangerous blind spots in acquisition, renewal, and licensing compliance decisions.
- Per-title content ROI remains one of streaming’s hardest unsolved measurement problems. Assigning meaningful monetary value to content on a service’s own platform is genuinely difficult, and most companies are still working with rough proxies.
- A large share of streaming catalog value is buried in titles that never surface because they’re not trending. Platforms that treat discovery as a trending-only problem are leaving real engagement – and retention value – on the table.
- Without a 360-degree view of user behavior across all services, recommendations, popularity signals, and retention models are built on incomplete data. The industry knows this is a problem and hasn’t solved it.
- Cross-catalog taxonomy is the unseen infrastructure problem. Comparing content performance across services is nearly impossible without a unified, consistently applied classification system.
- Data freshness is itself a competitive differentiator. The speed at which a service knows what is available – and where – directly determines how quickly it can act on that information.
Ask any streaming executive what they measure, and you’ll get a confident answer. Subscribers. Churn rate. Engagement hours. Content spend. These are the metrics every quarterly earnings call puts front and center.
Ask what they don’t measure well, and the conversation gets more interesting.
We put that question to the Reelgood team: what high-value insight about streaming catalogs, title availability, or discovery behavior do most services still fail to track?
The responses surfaced a set of blind spots that are, in several cases, more strategically significant than the metrics everyone already obsesses over.
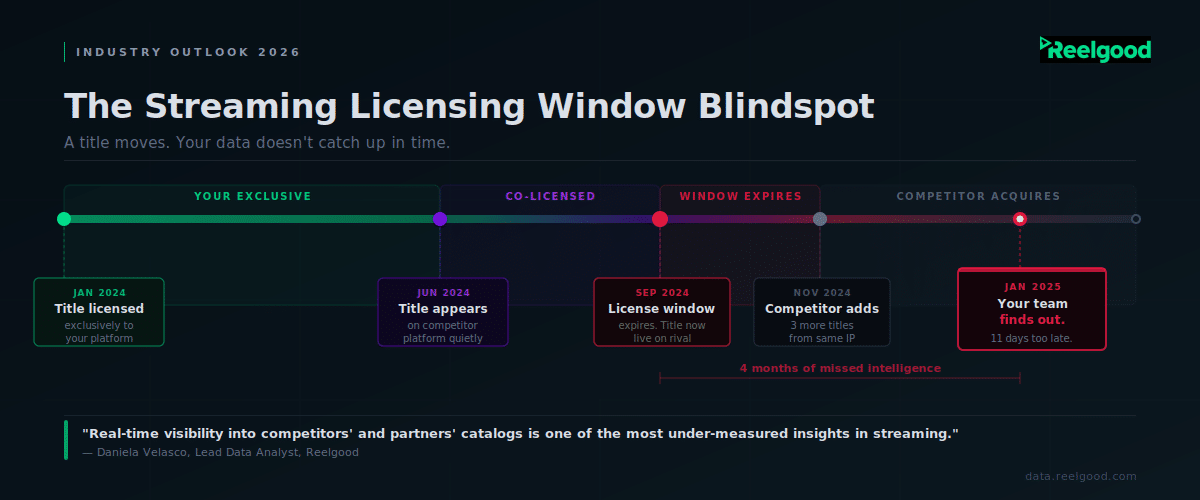
The Competitive Catalog Blind Spot
The most detailed response came from Daniela Velasco, Reelgood’s Lead Data Analyst, and it cuts to the core of how licensing decisions actually get made.
“One high-value insight many streaming services still don’t measure well is real-time visibility into competitors’ and partners’ catalogs,” she says. “This gap leads to blind spots in decision-making.
For example, Peacock may not know in real time which titles are currently available on Paramount+, potentially influencing content acquisition or renewal decisions based on incomplete information.
Similarly, HBO may not have immediate visibility into whether Netflix is strictly adhering to contracted licensing windows, increasing the risk of missed breaches or delayed enforcement.”
The problem isn’t that services don’t want this information. It’s that building and maintaining it is genuinely hard.
“Streaming catalogs change constantly, licensing windows are complex, and full catalogs are not easily accessible through public or first-party data alone,” Daniela explains. “Maintaining this view internally requires continuous crawling, normalization, and QA across hundreds of services – an expensive and operationally heavy lift.”
 The practical implication is significant.
The practical implication is significant.
Without a continuously updated view of the competitive landscape, content teams are making acquisition and renewal calls based on information that may be days, weeks, or months out of date. For a business where a single title can shift meaningful subscriber behavior, that lag is costly.
As Daniela frames it, a strong measurement approach “requires a centralized, continuously updated view of title availability across all major services, enriched with metadata and historical change tracking.”
The payoff: “replacing assumptions with data-driven clarity” across acquisition, licensing enforcement, and competitive positioning.
This is exactly the kind of cross-service catalog intelligence that Reelgood provides, and the reason it has practical value beyond basic content discovery.
The Per-Title ROI Problem
Diego Suarez, Data Analyst, points to a measurement problem that has quietly plagued streaming finance teams for years: how do you assign meaningful monetary value to a specific piece of content on your own platform?
“Streaming companies have a hard time with this metric because of the challenge that represents assigning a monetary value to content that is currently available on the company’s own streaming service,” he says. “It’s easier for content licensed to third parties, as the value is evident: what the other company is paying you for it.
However, for content on your own streaming service, there is no easy way to determine how much of the streaming service’s revenue can be assigned to that content.”
This is a real structural problem, and it matters for almost every major content decision a service makes.
When a service is deciding whether to renew a license, commission a sequel, or drop a title from its library, it is ideally working from a clear-eyed view of what that content is worth. In practice, the calculation involves a lot of inference and rough attribution.
Services that are closest to solving this problem do it by modeling a cluster of signals together: acquisition-driven sign-ups attributed to a title, churn protection when a title is available, and audience overlap analysis to understand which titles keep the same people engaged over time.
None of it is clean. All of it is better than not measuring it.
Dark Catalogs: The Value Hiding in Plain Sight
The streaming era has produced one of the most counterintuitive problems in media: services sit on enormous libraries of content that their own subscribers never find.
Liseth Mina Rosero from the data team captures the problem cleanly: “Most streaming services still miss how much great content is hiding in their own catalogs. Solid shows and movies never get surfaced because they’re not trending. Tracking what’s overlooked could help platforms promote smarter, reduce churn, and get more value out of the content they already have.”
Miguel Callejas, Lead on the Data Entry Team, approaches the same issue from the consumer side: “Huge catalogs are not always the best way to go. With so many options, consumers get lost and don’t know what to watch. Companies should focus on content that had good reviews from audiences and critics, and maintain quality season after season, rather than adding filler content that doesn’t add value. I think companies don’t measure consumer engagement correctly.”
Renato Avilés, Data Analyst, adds the discovery framing: “With so much content spanning all eras of film and television, the key challenge is showcasing the most relevant and attention-grabbing material,” a problem that gets harder, not easier, as catalogs grow.
This connects to what Mediagenix, citing the 2025 DPP Leaders Briefing, calls “effective catalog size” — the portion of a catalog that is actually exposed, discovered, and viewed.
By that measure, a service with 20,000 titles and poor discovery infrastructure may have an effective catalog far smaller than a service with 5,000 titles and sharp editorial and recommendation systems.
Catalog size doesn’t win. Effective catalog size does.
For platforms, this matters in a specific, actionable way: content that was acquired and is sitting unused still has a licensing cost, often a promotional cost, and definitely an opportunity cost.
Measuring what’s underleveraged — and building editorial workflows to surface it — is a retention and monetization strategy, not just a product nicety.
The Cross-Platform Blind Spot in User Behavior
Felipe Lemarie, Data Science Lead, identifies what may be the most structurally intractable measurement gap: streaming services only see what their own subscribers do on their own platform.
“Streamers don’t know what users see, add, or interact with across all their services. They just have what they do on their platforms,” he says. “A strong measurement approach would be the full user watch history across all services. That would improve user recommendations, retention, ad placement, and understanding of the true popularity of shows and movies.”
This is a gap the industry acknowledges and hasn’t meaningfully closed. Comscore’s 2025 State of Streaming report found the average household now streams content from 6.9 services. A recommendation engine operating on data from one of those services is making decisions with only 14% of the picture.
The implications are significant across multiple functions.
A service promoting a title as a “must-watch” may not know the subscriber already saw it on a competing platform. A churn model that predicts low-risk subscribers may not account for the fact that those subscribers have a robust viewing life elsewhere.
A content acquisition team that sees declining consumption of a genre in its own data may be missing that the genre is thriving – just on another platform.
Full cross-platform visibility isn’t realistic at the individual user level without explicit consent and industry-level data sharing agreements. What services can do is use aggregated, anonymized cross-platform signal data (available through data partners) to calibrate their first-party models and challenge the assumptions those models are built on.
Without Shared Taxonomy, None of It Scales
Pablo Lucio Paredes, Head of Engineering and Data, offers a response that sounds technical but has big strategic consequences: “Taxonomy across catalogs is virtually impossible to analyze without a centralized database with a taxonomy algorithm running on top of it to classify content.”
This is the infrastructure problem underneath almost every other measurement gap on this list.
Whether the goal is comparing competitive catalogs, analyzing discovery behavior across platforms, or building cross-service popularity signals, all of it requires a shared, consistent way of classifying content.
Without it, you’re comparing apples to oranges — or more precisely, comparing content labeled as “action” by one service’s internal system to content labeled as “thriller” by another, with no reliable way to normalize.
The problem is compounded by the fact that genre and category tags vary not just between services but over time within the same service. A title added to a catalog in 2018 may have been classified under different conventions than a title added in 2024, even on the same platform.
This is where a centralized, continuously maintained metadata layer – applied consistently across services – becomes foundational infrastructure rather than a nice add-on.
For any team trying to build cross-catalog analysis into their workflows in 2026, this is the unglamorous prerequisite.
Intent Gap: When the Right Title Isn’t There
Andres Fuertes Ruiz, Data Engineer, surfaces a subtler problem that sits at the intersection of discovery and metadata: measuring how well a title satisfies the intent behind a search, especially when the ideal title isn’t available.
“It is difficult because it requires mapping emotional metadata rather than just genres,” he says.
This is a real limitation of how most streaming discovery systems work today.
A user searching for “something like The Bear” has an intent that involves tone, pacing, emotional register, and thematic feel — not just the genre tag “drama.” A service that can only match on category will surface a lot of titles that technically qualify but miss the mark. A service with richer emotional and contextual metadata can get much closer to what the viewer actually wants.
This gap matters commercially when a highly anticipated title is unavailable — either because it hasn’t been licensed, or because its licensing window has ended.
The question of whether a substitute title can satisfy the viewer’s intent well enough to prevent a churn event is one most services can’t currently answer with precision.
As Andres frames it, addressing this requires moving beyond genre taxonomy toward what might be called emotional metadata: tags that capture mood, tone, pacing, and cultural register, applied consistently at scale.
It’s one of the harder data problems in streaming, and one of the more valuable ones to solve.
Data Freshness as a Competitive Asset
Andrés Granizo, QA and Data Entry Analyst, makes what sounds like an operational observation but is actually a strategic point: “How quickly we [Reelgood] can have the data updated, when a title becomes available. That’s because we can react as fast as possible when it’s needed.”
In an environment where content moves between platforms more rapidly than ever — driven by shorter windowing cycles, co-exclusivity deals, and the kind of dynamic licensing that several team members predicted in our catalog strategy post — the lag between when something changes and when your systems reflect that change is a direct competitive liability.
A service that knows a competitor just lost a major title can promote its own version immediately. A service that doesn’t find out until a weekly data refresh has already missed the window.
The Looper Insights Big Reset report, based on a survey of 61 senior streaming and CTV executives, puts it plainly: “success in 2026 will depend less on catalogue size alone and more on how effectively platforms adapt to new interfaces, behaviours and business models.”
Real-time availability intelligence is the operational expression of that shift.
What It Means Across the Industry
The gaps identified by the Reelgood team aren’t obscure edge cases.
They’re the measurement problems underneath the decisions that matter most in streaming right now:
- what to license,
- what to surface,
- what to renew, and
- how to retain subscribers
in an environment where the average household is choosing between nearly seven services.
What connects all of them is a common theme:
Most services are measuring their own platforms well, and the broader landscape poorly.
Per-title ROI, cross-platform behavior, competitive catalog intelligence, and effective catalog size are all problems that require data beyond what any single service generates on its own.
That’s a structural challenge and, for data providers, a structural opportunity.
The services that invest in external intelligence layers – to fill in the picture their own data can’t provide – are the ones best positioned to make faster, better-informed decisions as the industry continues to consolidate and compete.
The streaming services pulling ahead in 2026 aren’t necessarily the ones with the biggest catalogs. They’re the ones with the clearest view of what those catalogs are actually worth — and what their competitors are doing with theirs.
This post is part of a series on our team’s 2026 streaming industry predictions. Read more: How AI and Machine Learning Will Reshape Streaming in 2026 | Operational Intelligence: Why Streaming Teams Need Faster Answers | Metadata as a Strategic Asset: What Separates Leaders from Laggards