Streaming Availability Data Precision Analysis
LLM-Generated Availability vs. Verified Data
Key Findings
Half the time users ask an LLM where to watch something, they're directed to a service that no longer has the title, or miss a service that does have it available.
Reelgood's data correctly identified streaming service availability nearly twice as often as Claude and more than twice as often as ChatGPT.
The accuracy metric penalizes both false positives (listing services that don't carry the title) and false negatives (missing services that do), calculated per title and averaged across the full sample. See Section 3.4 for the precise formula.
The error patterns identified in this analysis are systematic, not random. Both LLMs exhibit consistent failure modes around outdated availability, transactional video-on-demand (TVOD) services, add-on/bundled services, less prominent streaming platforms, and title disambiguation. These patterns suggest structural limitations in how LLMs source and process availability data, rather than occasional mistakes.
Executive Summary
This report presents the findings of a controlled analysis comparing the accuracy of streaming title availability data ("where to watch" a movie or TV show) across three sources: Reelgood's proprietary data infrastructure, ChatGPT (version 5.2), and Claude (Haiku 4.5).
The analysis was conducted on March 5, 2026 using a random sample of 100 popular U.S. streaming titles (50 movies, 50 TV shows).
The results reveal a significant accuracy gap between Reelgood's verified data and LLM-generated availability responses.
Background and Objective
Large language models are increasingly used as a first point of contact for consumers seeking information about where to watch movies and TV shows. Queries like "Where can I watch [title]?" are among the most common entertainment-related prompts submitted to ChatGPT, Claude, and similar AI assistants.
Users tend to trust these responses at face value. When the underlying data is wrong, users get sent to a streaming service that no longer has the title or never did, or miss services where the title is actually currently available. This creates a poor user experience and undermines trust in the AI product itself.
Why LLM-generated availability data is unreliable. The training data and retrieval sources that LLMs draw from are structurally biased toward announcing when a title arrives on a streaming service. Entertainment press covers new additions to a catalog extensively, but rarely follows up when a title quietly leaves a catalog weeks or months later. The result is a corpus that skews heavily toward stale positives: the LLM confidently reports availability that no longer exists.
Why this is harder than it looks. The obvious solution would be to ingest catalog feeds directly from each streaming service. In practice, this creates a massive entity resolution problem. Every service uses its own internal ID system to identify content, so there is no universal key to join across catalogs. Simple title matching fails because multiple distinct titles share the same name and the same piece of content is often listed under different titles across services due to regional naming, translation, or rebranding. Matching on metadata is equally unreliable - fields expected to be consistent, like release year and runtime, vary more often than they agree. One streaming platform may list a film's theatrical release year, while another uses its streaming premiere date. Runtimes differ depending on whether credits, intros, or bumpers are included.
Resolving these catalogs into a single unified view of what's available requires domain-specific infrastructure that Reelgood has built and refined over nearly a decade.
Reelgood maintains a proprietary data infrastructure purpose-built for streaming availability tracking. This system monitors title catalogs across hundreds of streaming services in real time, covering SVOD (subscription), TVOD (transactional/rental), AVOD (ad-supported), and bundled/add-on services.
Objective: This analysis was designed to quantify the accuracy gap between LLM-generated streaming availability data and Reelgood's verified data, to identify the specific error patterns that drive that gap, and to present the findings in a way that is useful for the data and product teams at the respective LLM providers.
Methodology
3.1Sample Selection
A random sample of 100 popular titles was selected, comprising 50 movies and 50 TV shows. Titles were drawn from the top ~2,000 titles ranked by Reelgood's Streamability Score, which ranks content based on how available it is. Random selection within this pool ensured representation across release years, genres, and distribution patterns (i.e., titles available on a single service vs. titles distributed across many).
3.2Data Collection
For each title, availability data was collected from three sources on March 5, 2026:
- Reelgood: Programmatic retrieval from Reelgood's production databases, returning the full list of U.S. streaming services carrying each title. For TV series, a title was considered available on a service if at least one episode was present.
- ChatGPT (5.2, free tier): Each title was queried with the standardized prompt: "Where can I watch the movie/show [Title] today in the US? Reply only with the names of the services in one line separated by commas and ordered alphabetically." The structured output format was chosen to facilitate consistent tabulation across all 100 titles. Responses were manually recorded.
- Claude (Haiku 4.5, free tier): Same standardized prompt, same manual tabulation process.
3.3Ground Truth Construction
For each title, we constructed a verified ground truth by consolidating the union of all services mentioned across the three data sources. Each service in this consolidated list was then manually verified against the actual streaming platform to confirm whether the title was in fact available as of March 5, 2026. The resulting "correct availability list" served as the authoritative benchmark.
3.4Accuracy Measurement
Each data source was compared against the ground truth on a per-title, per-service basis. Errors were classified into two types:
- Type I Error (False Positive): The data source listed a service where the title is not currently available.
- Type II Error (False Negative): The data source failed to list a service where the title is actually available.
Both error types are penalized equally. For each title, accuracy is computed as:
Worked example: Suppose the film The Social Network is verified as available on Netflix, Hulu, HBO Max, and Peacock (T = 4). If Reelgood lists Netflix, Hulu, and Peacock (missing HBO Max), that is 1 error, yielding (4 - 1) / 4 = 75% accuracy. If Claude lists Netflix, Hulu, and Disney+ (missing HBO Max and Peacock, plus incorrectly adding Disney+), that is 3 errors, yielding (4 - 3) / 4 = 25% accuracy.
The overall accuracy score for each data source is the simple average of title-level accuracies across all 100 titles. This approach penalizes errors proportionally to the total number of valid services per title, rather than treating each title as a binary pass/fail.
3.5Scope
All major SVOD, TVOD, and AVOD services monitored by Reelgood active in the U.S. market were included.
Results
4.1Overall Accuracy
| Data Source | Average Accuracy |
|---|---|
| ChatGPT (5.2) | 43.76% |
| Claude (Haiku 4.5) | 50.21% |
| Reelgood | 96.89% |
Reelgood's data was nearly twice as accurate as Claude and more than twice as accurate as ChatGPT on average across the sample.
The 46-53 percentage point gap between Reelgood and the two LLMs is substantial and consistent across both movies and TV shows.
4.2Error Pattern Analysis
The errors observed in ChatGPT and Claude responses were not random. They cluster around several consistent patterns that suggest structural limitations in how these models process streaming availability information.
| # | Pattern | Description |
|---|---|---|
| 1 | Stale Availability | Titles are shown on services in which they have already left |
| 2 | Add-On and Bundle Confusion | Add-ons reported as the standalone service, e.g., a Starz-via-Prime-Channel title shows as "Prime Video" |
| 3 | Long-Tail Service Gaps | Free and ad-supported services like Tubi, Pluto TV, Hoopla, and Kanopy consistently missed |
| 4 | SVOD/TVOD Conflation | Subscription and rental/buy tiers on the same platform treated interchangeably |
| 5 | TVOD Blindness | Rent/buy options from Apple TV Store, Amazon, etc. are systematically omitted |
| 6 | Title Disambiguation | Availability conflated across different versions of same-name titles |
Pattern 1:Stale Availability
Models confidently report titles as currently streaming on services they've already left. The cause is structural: entertainment press covers new additions to a catalog extensively but rarely follows up when a title quietly leaves weeks or months later. The training corpus skews heavily toward those announcements, so the model treats outdated positives as current. This is the most pervasive error pattern observed.
Pattern 2:Add-On and Bundle Confusion
When a title is available through a bundled or add-on service (e.g., Paramount+ via Prime Video, or Hulu via Disney+ bundle), the LLMs frequently either miss the add-on availability or incorrectly attribute it to the standalone service. For example, a model might list "Prime Video" for a title that is only available through the Paramount+ add-on channel within Prime Video. This conflation is a meaningful error: a user subscribing only to base Prime Video would not be able to watch the title.
Pattern 3:Long-Tail Service Gaps
The LLMs struggle significantly with smaller or less prominent services (e.g., Fawesome, Pluto TV, Hoopla, Kanopy, Tubi). These platforms collectively carry a substantial volume of content and represent real viewing options for users, but they appear to be underrepresented in the models' training data.
Pattern 4:SVOD/TVOD Conflation
When a platform operates both an SVOD tier and a TVOD storefront (e.g., Apple TV subscription vs. Apple TV Store rentals, or Amazon Prime Video vs. Amazon Video rent/buy), the LLMs frequently fail to distinguish between the two. A model might report that a title is available on "Apple TV" without specifying whether that refers to the subscription service or the rental store. In many cases, the title is only available on one of the two, making the ambiguous response functionally incorrect.
Pattern 5:TVOD Blindness
Both LLMs systematically underreport transactional video-on-demand (rent/buy) availability. When a title is available for purchase or rental on platforms like Amazon Video or the Apple TV Store, the LLMs frequently omit these options entirely. This suggests the models are biased toward subscription-based services, likely reflecting the distribution of training data where editorial coverage skews heavily toward SVOD platforms.
Pattern 6:Title Disambiguation Failures
For titles with multiple versions (e.g., the 2023 live-action "One Piece" on Netflix vs. the long-running anime), both LLMs occasionally conflate the two, listing services for the wrong version. This type of error is particularly problematic because it appears authoritative while directing users to entirely the wrong content.
4.3Reelgood Data: Transparency on Residual Errors
Reelgood's 96.89% accuracy reflects a small number of residual errors. These fell into identifiable categories that have since been addressed:
Certain Roku catalog entries incorrectly included titles that were only available through optional add-on channels (e.g., Paramount+ via Roku). Additionally, YouTube's free-tier catalog had gaps where titles were in fact available. Both issues were identified during this analysis and have been corrected in Reelgood's production data pipeline.
Reelgood's error rate is not zero, but the errors are narrow, identifiable, and correctable through infrastructure improvements. By contrast, the LLM error patterns described above are structural and systemic, reflecting fundamental limitations in how these models source and process real-time catalog data.
Representative Examples
The following examples illustrate the error patterns identified in Section 4. For each title, we show the actual responses from ChatGPT, Claude, and the Reelgood-verified availability. All data was captured on March 5, 2026.
5.1TV Show
One Piece (2023)
Both ChatGPT and Claude confused the 2023 live-action Netflix series with the long-running anime, incorrectly listing Crunchyroll and Hulu as valid sources. Claude additionally listed "Crunchyroll Amazon Channel" and "TV Guide" as sources. Reelgood correctly identified the title as a Netflix exclusive (available on Netflix and Netflix with Ads). This is a clear title disambiguation failure, where the models could not distinguish between two distinct productions sharing the same name.
ChatGPT (5.2) response:
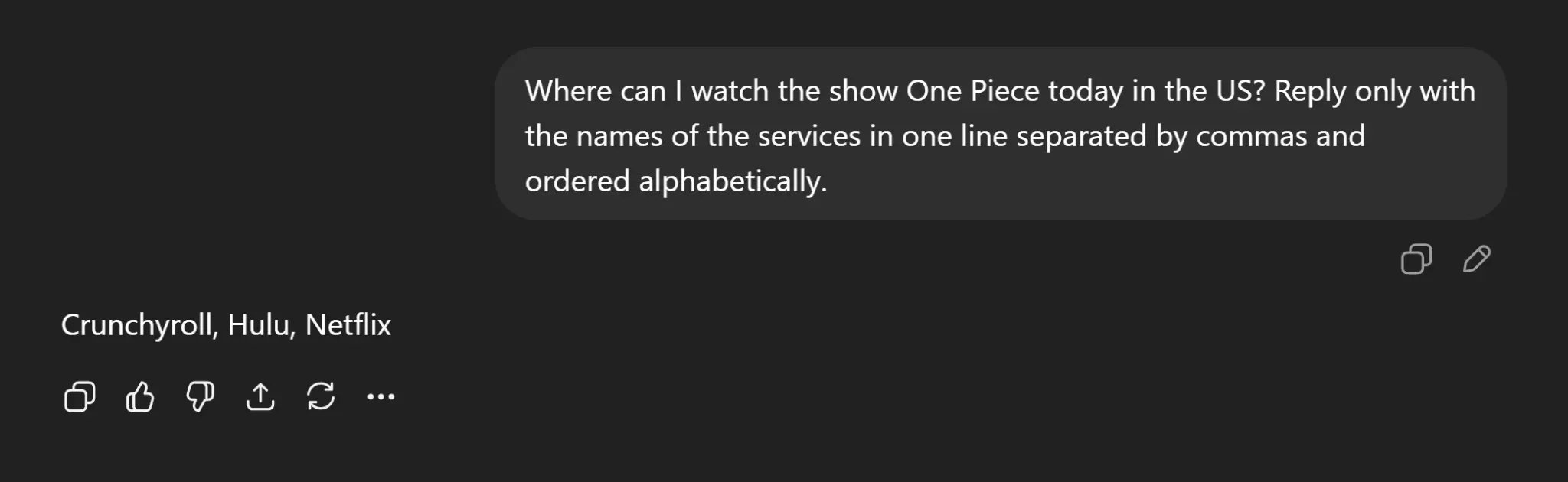
Claude (Haiku 4.5) response:

Reelgood verified availability:
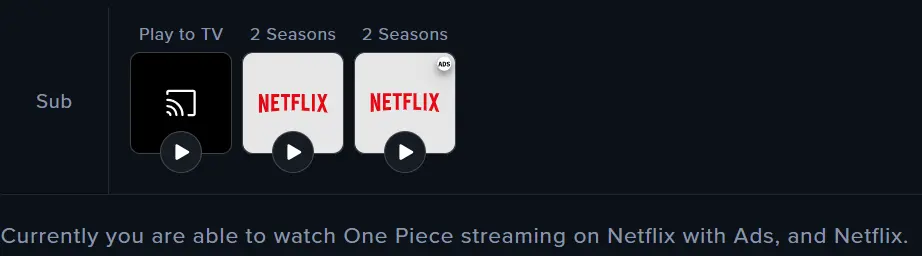
5.2Movie
The Omen (1976)
ChatGPT incorrectly listed Hulu as a source, and Claude incorrectly listed Netflix. In both cases, the title wasn't actually available on the platform they named.
ChatGPT (5.2) response:
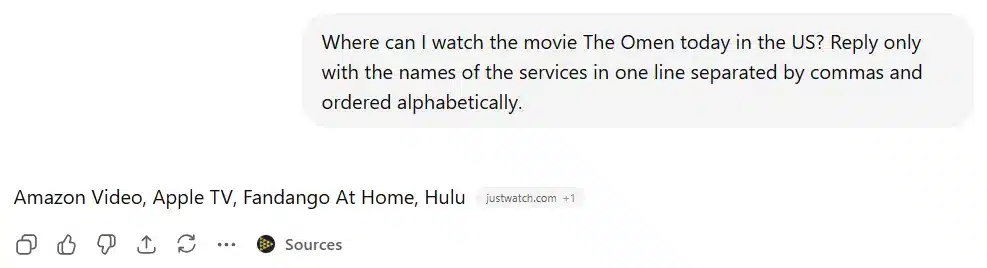
Claude (Haiku 4.5) response:

Reelgood verified availability:
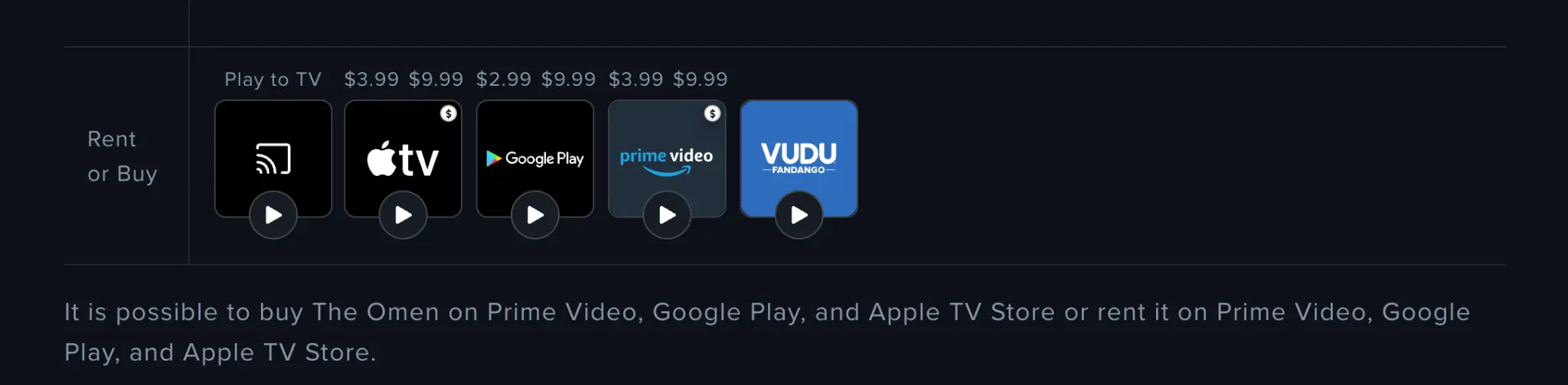
Technical Implications
The error patterns documented in this analysis point to several structural challenges facing LLMs in the domain of streaming content availability:
6.1Training Data Limitations
Streaming availability is highly dynamic. Titles move between services frequently, and catalog changes (especially removals) are rarely covered by the editorial sources (news articles, blog posts, reviews) that form the bulk of LLM training data. As a result, LLMs tend to reflect a stale, incomplete, and editorially biased view of which titles are available where. Services that receive less press coverage (AVOD platforms, niche SVOD services, TVOD storefronts) are systematically underrepresented.
6.2Retrieval-Augmented Generation (RAG) Considerations
Even with RAG pipelines, the quality of availability responses is fundamentally constrained by the quality and freshness of the underlying data source. If the retrieval layer draws from aggregated web content rather than a purpose-built, real-time catalog monitoring system, the same error patterns will persist. The granularity required for availability data (distinguishing SVOD from TVOD, base subscriptions from add-ons, regional variations) exceeds what general-purpose web scraping or editorial aggregation can reliably deliver.
6.3User Impact
LLMs can break trust with users via several types of incorrect query responses:
- Wrong service - LLM says a title's on Netflix. The user goes to Netflix; it's not there.
- Missing obvious availability - LLM omits a flagship pairing the user already knows (e.g., Game of Thrones not listed on HBO Max).
- Unnecessary spend - LLM tells the user to rent or buy a title that's actually free on a service they already subscribe to. The user pays - and later finds out they had access.
- Silent misses - LLM says a title isn't available (or isn't on any of the user's services), so they skip it. They later discover it was on one of their subscribed services all along.
For the LLM providers, these errors represent a measurable quality gap in one of the most common entertainment queries, and one that is resolvable with the right data partnership.
Conclusion
This analysis demonstrates a clear and quantifiable accuracy gap between LLM-generated streaming availability data and verified, purpose-built availability data. Reelgood achieved 96.89% accuracy compared to 50.21% for Claude and 43.76% for ChatGPT across a representative sample of 100 popular U.S. titles.
The errors are not random. They follow consistent, identifiable patterns rooted in the structural limitations of how LLMs source and process real-time catalog information. These patterns - stale availability, add-on confusion, long-tail service gaps, SVOD/TVOD conflation, TVOD blindness, title disambiguation failures, and occasional hallucinations - are addressable, but not through improvements to the language model alone. They require access to a verified, continuously updated data source that is purpose-built for this domain.
Reelgood's data infrastructure was designed specifically to solve this problem. We welcome the opportunity to discuss how this data can be integrated to improve the accuracy of streaming availability responses for LLM users.
Analysis Parameters
| Parameter | Value |
|---|---|
| Analysis Date | March 5, 2026 |
| Sample Size | 100 titles (50 movies, 50 TV shows) |
| Sample Source | Random selection from top ~2,000 titles by Reelgood Streamability Score |
| ChatGPT Version | 5.2 (free tier) |
| Claude Version | Haiku 4.5 (free tier) |
| Region | United States |
| Prompt Format | "Where can I watch the movie/show [Title] today in the US? Reply only with the names of the services in one line separated by commas and ordered alphabetically." |
| Accuracy Metric | Per-title: max(0, (T - E) / T), where T = true services, E = total errors. Averaged across 100 titles. |
| Error Types | False Positive (listed but not available) and False Negative (available but not listed) |
For questions about this analysis or to discuss data integration opportunities, contact Reelgood at data@reelgood.com
© Copyright 2026. All rights reserved.
T&C | Privacy Policy
© Copyright 2026. All rights reserved.
T&C | Privacy Policy